vLLM
vLLM⚓︎
vLLM 是面向大语言模型的高吞吐、内存高效推理与服务引擎。1Panel 在 AI -> 模型 -> vLLM 页面提供可视化管理能力,可用于统一创建、编辑、启停和维护本地 vLLM 服务。
该功能属于 1Panel 专业版。
1 前置条件⚓︎
在创建 vLLM 服务前,请先确认以下条件已满足:
- 服务器已安装 NVIDIA 显卡驱动,且执行
nvidia-smi可以正常查看显卡信息 - 已按照 NVIDIA 官方文档安装并配置
NVIDIA Container Toolkit - Docker 已具备 GPU 运行能力
- 已提前将需要加载的模型文件放置到服务器本地目录中
如需先检查 GPU 是否可用,可参考 GPU 监控 文档。
2 创建 vLLM 服务⚓︎
打开 1Panel 面板后,进入 AI 菜单,在 模型 页面切换到 vLLM 标签页,点击 创建。
按页面要求填写 vLLM 的部署参数后,点击 确认 即可开始创建。创建过程会以任务的方式在后台执行,完成后可在列表中查看服务状态。
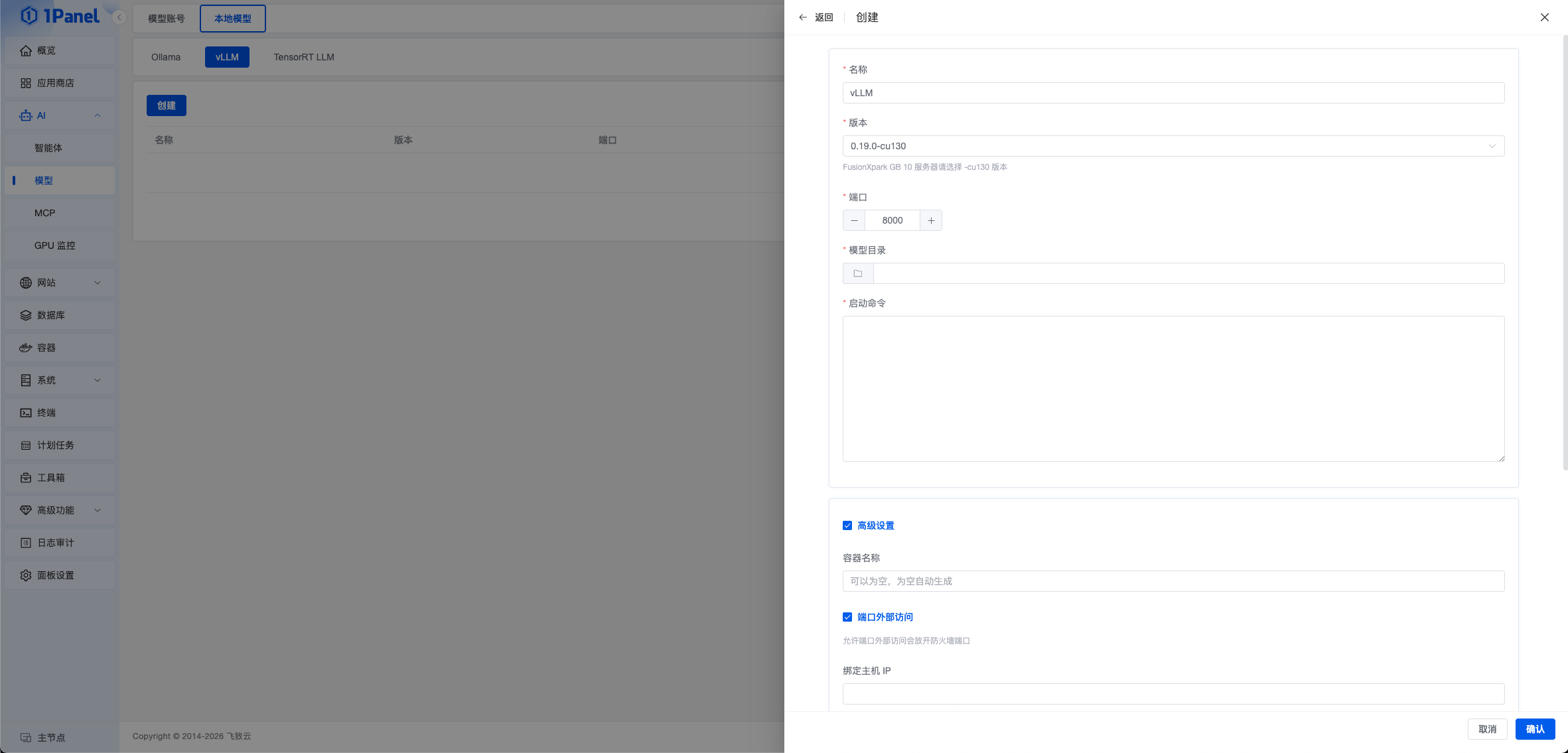
参数说明
- 名称:vLLM 服务名称,用于列表展示与后续管理
- 版本:选择需要部署的 vLLM 应用版本。
FusionXpark GB 10服务器请优先选择-cu130版本 - 端口:vLLM 服务对外提供 API 的端口,默认可使用
8000 - 模型目录:服务器上的本地模型目录。选择后,1Panel 会将该目录挂载到容器中
- 启动命令:用于启动 vLLM 服务的命令参数。选择模型目录后,系统会根据目录名称自动生成默认命令;如有特殊推理参数需求,也可自行调整
vLLM 服务创建完成后,会以 OpenAI 兼容接口的形式对外提供推理能力,便于后续接入智能体或其他 AI 应用。
3 高级设置⚓︎
如需对容器运行方式做进一步控制,可展开 高级设置。
高级设置说明
- 容器名称:自定义 vLLM 容器名称,默认会跟随服务名称自动填写
- 端口外部访问:开启后会放开防火墙端口,允许通过外部网络访问该服务
- 绑定主机 IP:用于限制端口只绑定到指定主机地址或网卡;如果不清楚用途,建议保持默认
- 重启策略:配置容器异常退出后的重启方式
- CPU / 内存限制:限制 vLLM 容器可使用的主机资源
- 拉取镜像:在启动前主动执行镜像拉取,确保使用目标版本镜像
- 编辑 compose 文件:允许手动调整部署使用的 Compose 配置;该选项适合有经验的用户,修改不当可能导致创建失败